Introduction
There is a lot of confusion in the industry around AI.
Many people hear the word AI and immediately think about ChatGPT, large language models, GPUs, or some form of magical intelligence running somewhere in the cloud.
However, in my personal opinion, the real challenge is not just the model.
The real challenge is the infrastructure underneath the model.
You can have the best AI model in the world, but if the compute, network, storage, security, and operational tooling is not designed correctly, the platform will struggle. This is where the modern data center becomes extremely important.
AI does not remove the need for data center engineering.
It makes data center engineering more important.
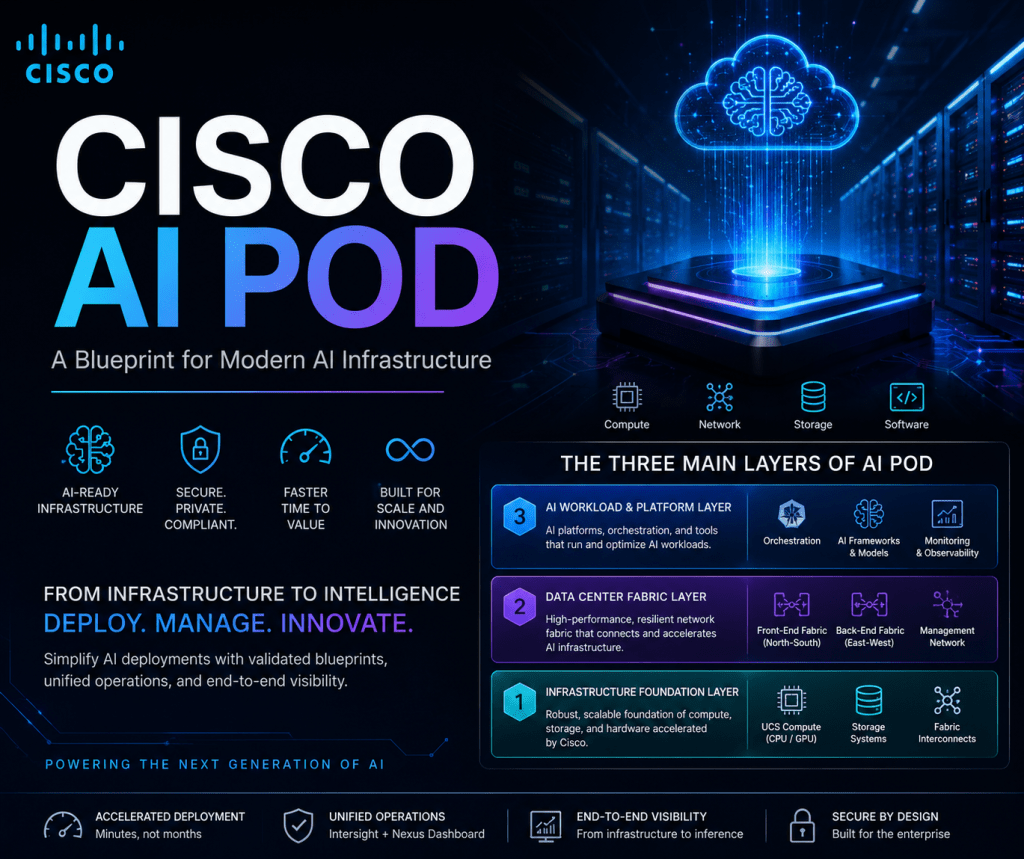
This is why I find Cisco AI POD interesting. It is not simply a collection of GPU servers. It is a validated infrastructure approach that brings together compute, networking, storage, orchestration, and operational management.
The key point is this:
AI infrastructure should not be built as a random collection of hardware.
It should be built as a repeatable platform.
The Problem with AI Infrastructure
When organisations start looking at AI, the conversation often starts with the model.
Which LLM should we use?
Should we use RAG?
Should we fine-tune?
Should we run inference locally?
Should we connect agentic applications to internal systems?
These are all valid questions. However, before any of this becomes useful, the infrastructure needs to exist.
That means GPU servers need to be prepared.
Fabric Interconnects need to be configured.
The data center fabric needs to be ready.
Storage needs to hold models, datasets, logs, checkpoints, and enterprise data.
The orchestration platform needs to run the workloads.
The operations team needs visibility.
Security teams need control.
This is where things become time consuming.
Building this manually is not a small task. It requires data center networking knowledge, compute knowledge, UCS knowledge, storage knowledge, AI workload understanding, and operational tooling.
This is why validated designs matter.
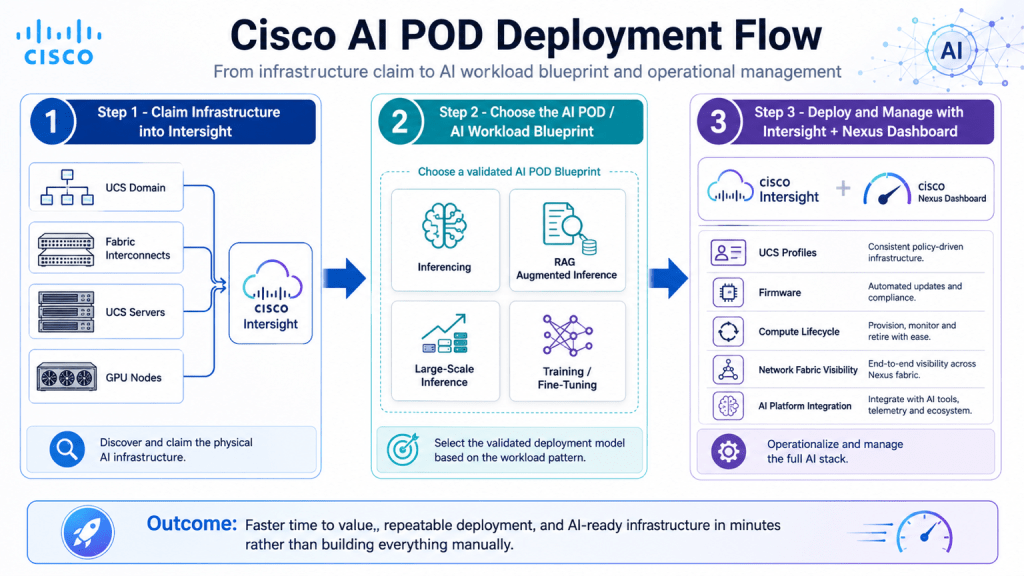
Step 1: Claim Infrastructure into Intersight
The first stage in the Cisco AI POD workflow is to claim the infrastructure into Cisco Intersight.
This includes the UCS domain, Fabric Interconnects, UCS servers, and GPU nodes.
In a UCS environment, the Fabric Interconnect is extremely important because it forms the control point between the servers and the wider data center infrastructure. The servers connect into the Fabric Interconnect pair, and that pair forms the UCS domain.
Once the UCS domain is claimed into Intersight, the infrastructure becomes visible and manageable from a central platform.
This is a powerful concept.
Instead of treating every server as a separate island, the infrastructure can now be managed as a consistent domain.
For me, this is where the theory starts becoming practical.
The theory says we need GPU compute.
The implementation shows that GPU compute still needs proper lifecycle management, firmware control, profile-based configuration, and operational visibility.
That is the value of Intersight.
It does not run the AI model itself.
It manages the UCS compute foundation that allows the AI model to run properly.
Step 2: Choose the AI POD or AI Workload Blueprint
The second stage is choosing the correct AI POD or workload blueprint.
This is where the design becomes workload-driven.
Not every AI workload is the same.
Inference is different from training.
RAG is different from large-scale inference.
Fine-tuning is different from simply serving a model.
This is something many people miss.
For inference, the requirement is usually about serving the model reliably to users or applications. The focus is latency, availability, scaling, and integration with customer applications.
For RAG augmented inference, the model is only one part of the solution. You also need access to enterprise data, vector databases, document stores, retrieval pipelines, and secure data access.
For large-scale inference, the focus becomes scale, concurrency, performance, and consistent service delivery.
For training or fine-tuning, the infrastructure requirement becomes much heavier. GPU-to-GPU communication, backend fabrics, RDMA, RoCEv2, storage performance, and checkpointing become far more important.
This is why the blueprint approach matters.
Instead of building everything from scratch, the platform starts from a validated workload pattern.
That pattern could be:
Inference.
RAG augmented inference.
Large-scale inference.
Training or fine-tuning.
The benefit of this approach is that the infrastructure is not designed blindly. It is aligned to the actual AI workload.
Step 3: Deploy and Manage with Intersight and Nexus Dashboard
The third stage is where Cisco Intersight and Nexus Dashboard help deploy and manage the stack.
This is important because AI infrastructure is not just about installation.
It is about ongoing operations.
Intersight focuses on the UCS compute side.
This includes UCS profiles, firmware, compute lifecycle, server health, inventory, policies, and repeatable configuration.
Nexus Dashboard focuses more on the data center fabric side.
This includes network fabric visibility, operational telemetry, assurance, and integration with the broader Cisco data center portfolio.
Together, they provide a more complete operational model.
Intersight gives visibility and control of the compute foundation.
Nexus Dashboard gives visibility into the network fabric.
The AI platform then sits on top of this foundation.
This is the part I personally find powerful.
The infrastructure is not just deployed.
It is managed.
It is visible.
It is repeatable.
It can be operated.
That is the difference between a lab experiment and an enterprise AI platform.
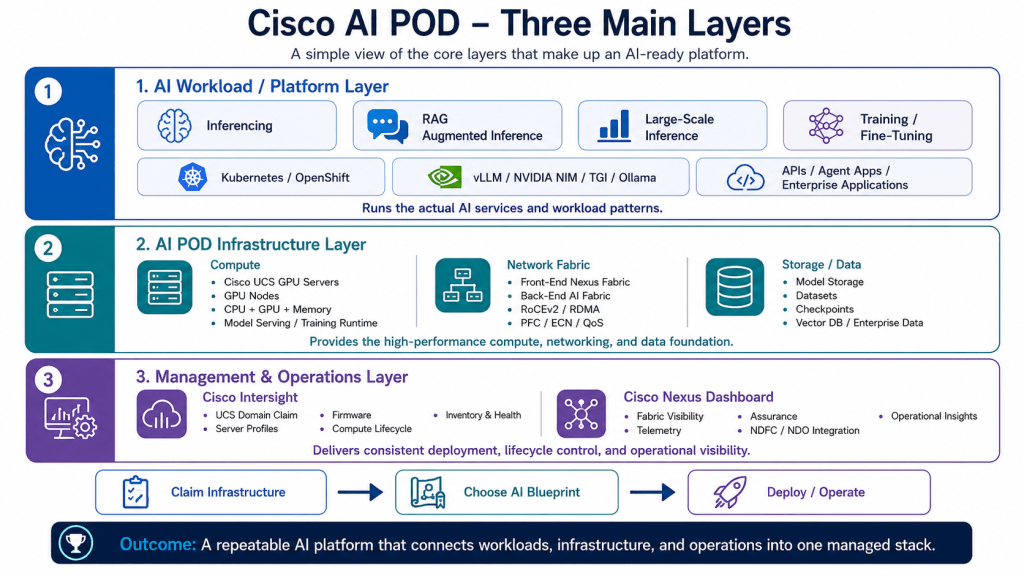
How the AI POD Connects to the DC Infrastructure
The Cisco AI POD does not sit in isolation.
It connects into the client’s existing data center infrastructure through the front-end network.
This front-end network is where users, applications, APIs, storage, Kubernetes, OpenShift, DNS, authentication, load balancers, and security services connect.
The backend network is different.
The backend fabric is used for GPU-to-GPU traffic, especially for training and fine-tuning workloads. This is where technologies such as RoCEv2, RDMA, PFC, ECN, QoS, and congestion control become important.
A simple way to look at it is this:
The front-end fabric connects the AI POD to the business.
The backend fabric connects the GPUs to each other.
This separation matters.
Inference and customer agent applications will usually use the front-end fabric heavily because users and applications need to reach the model endpoint.
Training workloads will use the backend fabric heavily because GPUs need to synchronise during the training process.
Again, the infrastructure design depends on the workload.
Why Running AI Locally Matters
Running AI locally has a number of advantages.
The first is control.
The organisation has more control over where the model runs, where the data sits, and how access is governed.
The second is data privacy.
For many organisations, sending sensitive data to an external cloud AI service may not be acceptable. Running the model locally allows the organisation to keep the data closer to its own infrastructure and security controls.
The third is performance.
For some use cases, especially internal applications and agentic workflows, having the model closer to the enterprise systems can reduce unnecessary dependency on external services.
The fourth is integration.
Local AI can be integrated with internal systems, private data sources, monitoring platforms, automation tools, and operational workflows.
This is where customer agent applications become interesting.
An agent application is not just a chatbot.
It may need to query internal documents, call APIs, check operational status, retrieve logs, interact with business systems, or support engineers with decision-making.
For this to work properly, the AI infrastructure must be close to the data and systems it needs to interact with.
Why This Is Usually Time Consuming
Building AI infrastructure manually can take a long time because there are many moving parts.
You need GPU servers.
You need firmware consistency.
You need server profiles.
You need networking.
You need storage.
You need security.
You need orchestration.
You need model-serving software.
You need telemetry.
You need operational ownership.
You need integration into the existing enterprise environment.
Each of these areas has its own complexity.
If the network is not configured correctly, AI performance can suffer.
If storage is too slow, model loading, training data access, and checkpointing can suffer.
If the servers are not consistently configured, troubleshooting becomes harder.
If there is no visibility, the operations team will struggle when something fails.
This is why AI infrastructure is not just a GPU purchase.
It is a data center architecture problem.
Why Cisco AI POD Changes the Conversation
Cisco AI POD is interesting because it gives organisations a more structured starting point.
Instead of spending months trying to understand every infrastructure decision from scratch, the organisation can start with a validated architecture and a workload-aligned blueprint.
That does not mean there is no design work.
There will always be design decisions.
But it reduces the amount of guesswork.
It helps organisations move quicker from idea to implementation.
It gives the infrastructure team a more repeatable model.
It gives the AI team a platform they can actually consume.
It gives the operations team visibility and lifecycle management.
That is the real value.
The goal is not just to have AI.
The goal is to have AI that can be deployed, managed, secured, and operated properly.
Conclusion
Cisco AI POD is not just about GPUs.
It is about turning AI infrastructure into a repeatable data center platform.
The workflow is simple to understand.
First, claim the infrastructure into Intersight.
Then choose the correct AI POD or workload blueprint.
Then deploy and manage the stack with Intersight and Nexus Dashboard.
This is important because modern AI infrastructure needs more than compute.
It needs consistent UCS management.
It needs proper data center fabric visibility.
It needs storage integration.
It needs orchestration.
It needs security.
It needs operational control.
In my opinion, this is where data center engineers have a strong advantage.
We already understand the foundation AI depends on.
AI does not make data center knowledge less relevant.
It makes it more valuable.
The model may get the attention.
But the infrastructure determines whether the AI platform can actually run, scale, and survive in the real world.




Leave a comment